作为 Python 爬虫的入门教程,我想有必要来个爬虫程序压压惊,爬取性感美女的图片,然后保存到自己的电脑里面。爽歪歪~
先看下效果吧,这是我把爬取的图片自动存储到的文件夹里边:

爬虫三步骤:抓取,分析,存储。
抓取
首先我们要有个目标对吧,我们想要抓取美女照片,就去找找看哪里的网站妹纸多,那咱们就从哪里下手呗。
我发现这网站 http://www.meizitu.com 的妹纸图不错啊,那还等什么,抓取呗。
在 python 中有个叫做 requests 模块,直接 pip install 就可以了,然后访问这个网址获取相应的源码:
1 | response = requests.get(url) |
比如我想获取性感美女的源码,那么我的 url 就是 http://www.meizitu.com/a/sexy_1.html 通过get请求我们就可以获取返回的响应体了,我们通过response.text就可以或源码。部分源码截图如下:
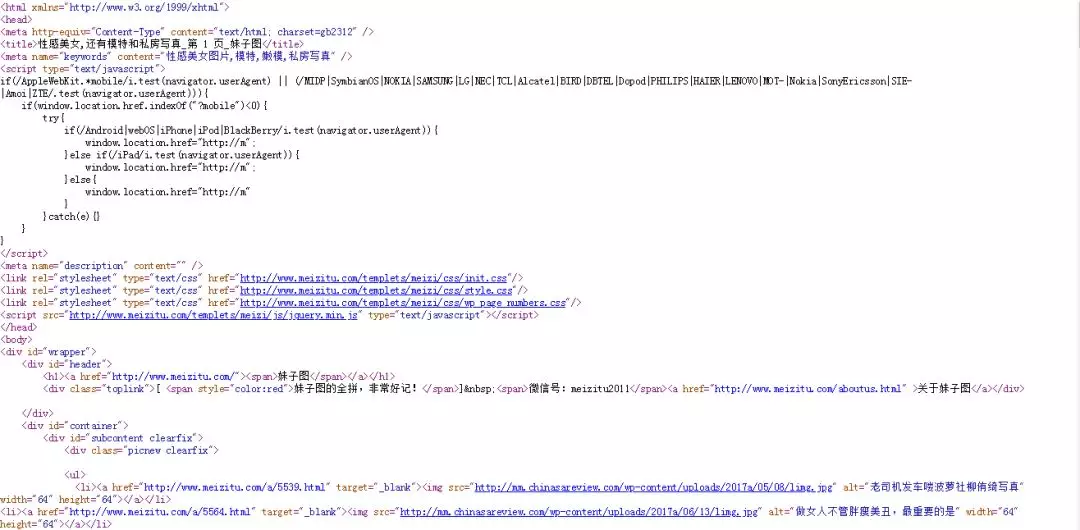
分析
抓取完了之后,我们对我们感兴趣的内容要进行分析了,这时候就涉及到「正则表达式」,根据我们定义的一些规则,来获取我们想要的内容。
我们现在当然是对返回源码中的美女图片感兴趣啦,从返回的源码中就可以看到,美女的图片都是包裹在 img 标签中的:
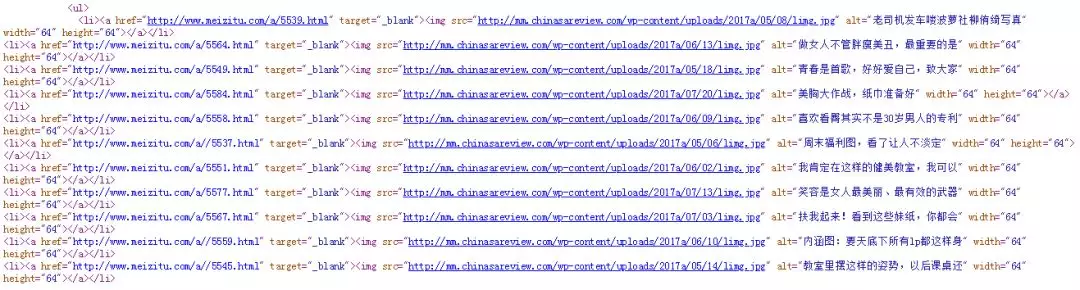
那么我们就可以用 re 模块来匹配获取我们想要的图片链接了:
1 | p = r'<img src="([^"]+\.jpg)"' |
获取到的部分图片链接截图:
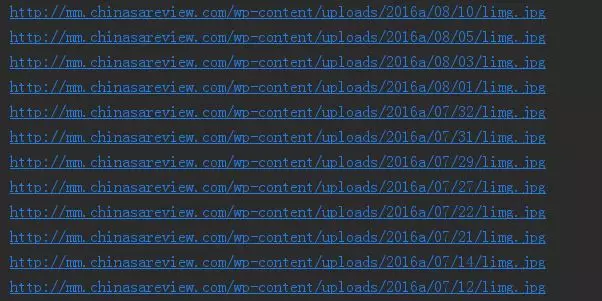
存储
既然获取到图片链接了,那么接下来就可以存储了,这里暂时存储到自己本地电脑上吧:
1 | with open(filename,'wb') as f: |
ok,这样就完成了,是不是很简单?当然爬虫说简单也简单,说复杂也复杂,关键是要看自己想做什么事情,如果你从这个例子中发现自己对 python 又多了些许兴趣,那不妨多关注我,我往后给你写一些 python爬虫 所需要的知识点,例如其它的爬虫模块如Scrapy ,一些表单的请求参数,反爬虫,cookie,多进程抓取等等。
专门为 Python 开了个公众号:学习python的正确姿势 ,在里面发送 「meizi」获取抓美女的源代码吧。
不说了,我再去抓取多一点美女的图片了。
