想看好书?想知道哪些书比较多人推荐,最好的方式就是看数据,接下来用 Python 爬取当当网五星图书榜 TOP500 的书籍,或许能给我们参考参考!
Python爬取目标
- 爬取当当网前500本受欢迎的书籍
- 解析书籍名称,作者,排名,推荐程度和五星评分次数数据。
- 将数据存写入到本地文件
分析网页
在当当网五星图书榜这个网址中,我们可以看到这里列出来了五星图书榜:
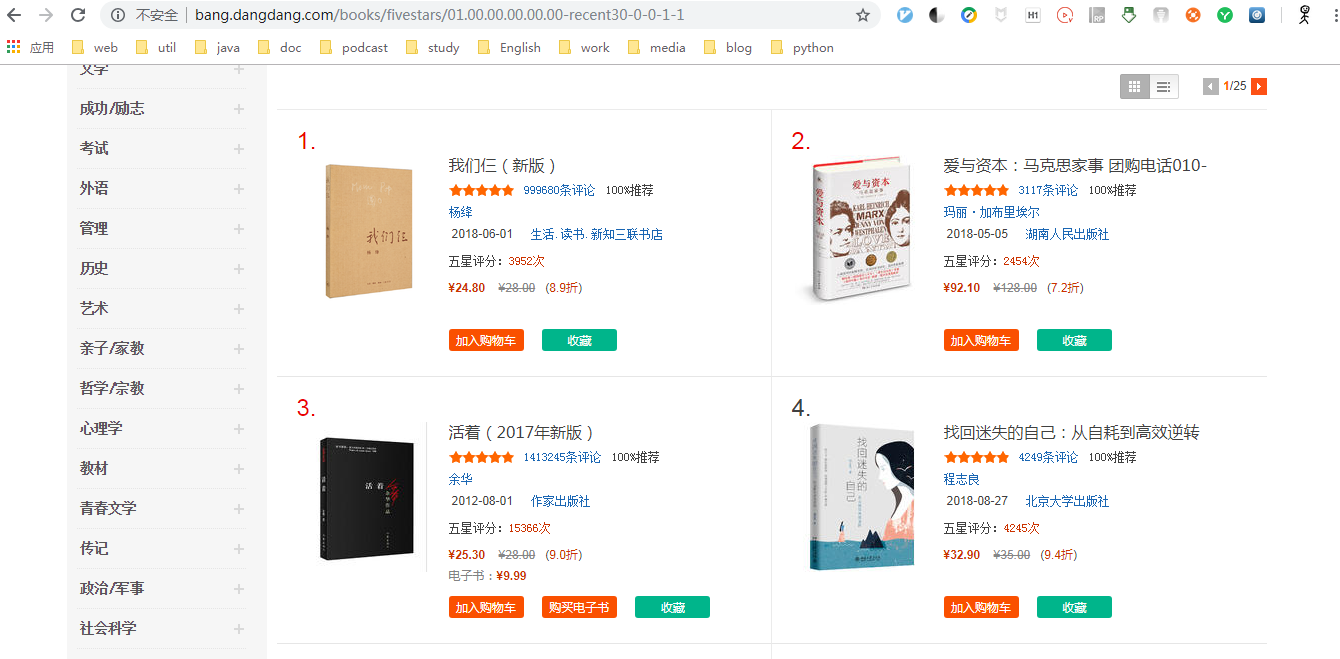
通过源码可以看到,我们想要的信息被包裹在<li>标签中:
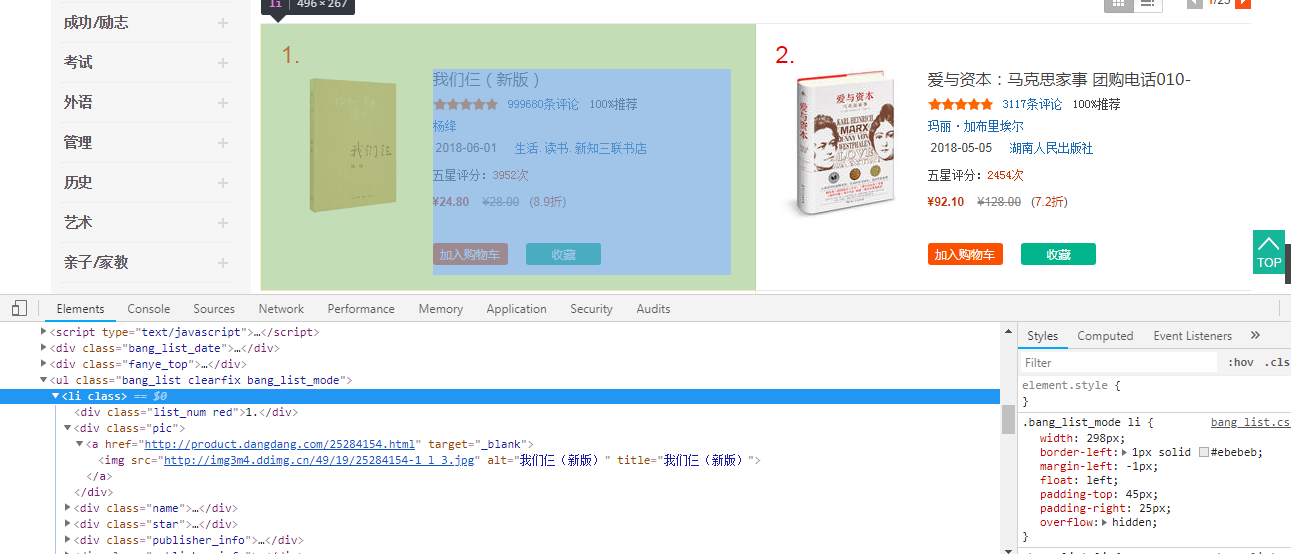
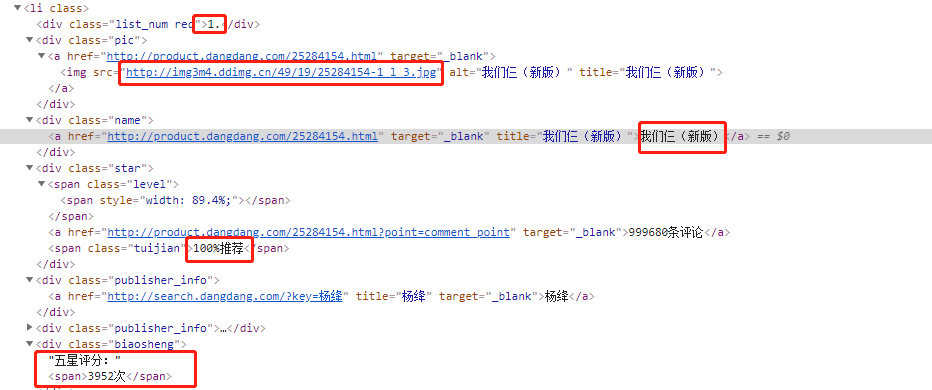
可以看到我们要的这些数据都在这:
当我们点击下一页的时候,url 地址会发生改变(最后的数字会加1):
第一页的 url 是:http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-1
第二页的 url 是:http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-2
…
我们等会可以通过这个变量来实现多页加载数据。
Python请求网页
我们使用 requests 来请求当当网的地址,定义一个get_one_page,将会返回 HTML 源代码。
1 | def get_one_page(url): |
打印出来就是这样,部分截图如下:

正则解析
源代码那么多数据,但是对我们来说只需要籍名称,作者,排名,推荐程度和五星评分次数数据,所以我们要用正则表达式来过滤一下,使用 re 模块,定义匹配规则:
1 | <li>.*?list_num.*?>(.*?)</div>.*?pic.*?src="(.*?)".*?/></a>.*?name"><a.*?title="(.*?)">.*?tuijian">(.*?)</span>.*?publisher_info.*?title="(.*?)".*?biaosheng.*?<span>(.*?)</span>.*?</li> |
定义 parse_one_page ,返回每次匹配到的数据,解析成字典形式:
1 | def parse_one_page(html): |
将数据写入文件
我们已经拿到了每次请求的数据,并且解析匹配好了,那么将每次得到的数据写入book.txt文件中去:
1 | def write_content_to_file(content): |
多页请求
我们要获取 TOP500 ,当当网每页给出 20 条数据,我们需要 25 页的数据,一开始我们在分析网页的时候知道 URL 会选择页数改变最后的参数,所以我们可以用循环来请求所有的数据:
1 |
|
运行爬取
可以看到我们将五百条数据抓取下来了,并且在项目中多了一个book.txt文件,打开看看有没将数据写入:
ok,以上我们就把当当网最受欢迎的 500 本书爬取下来了!
