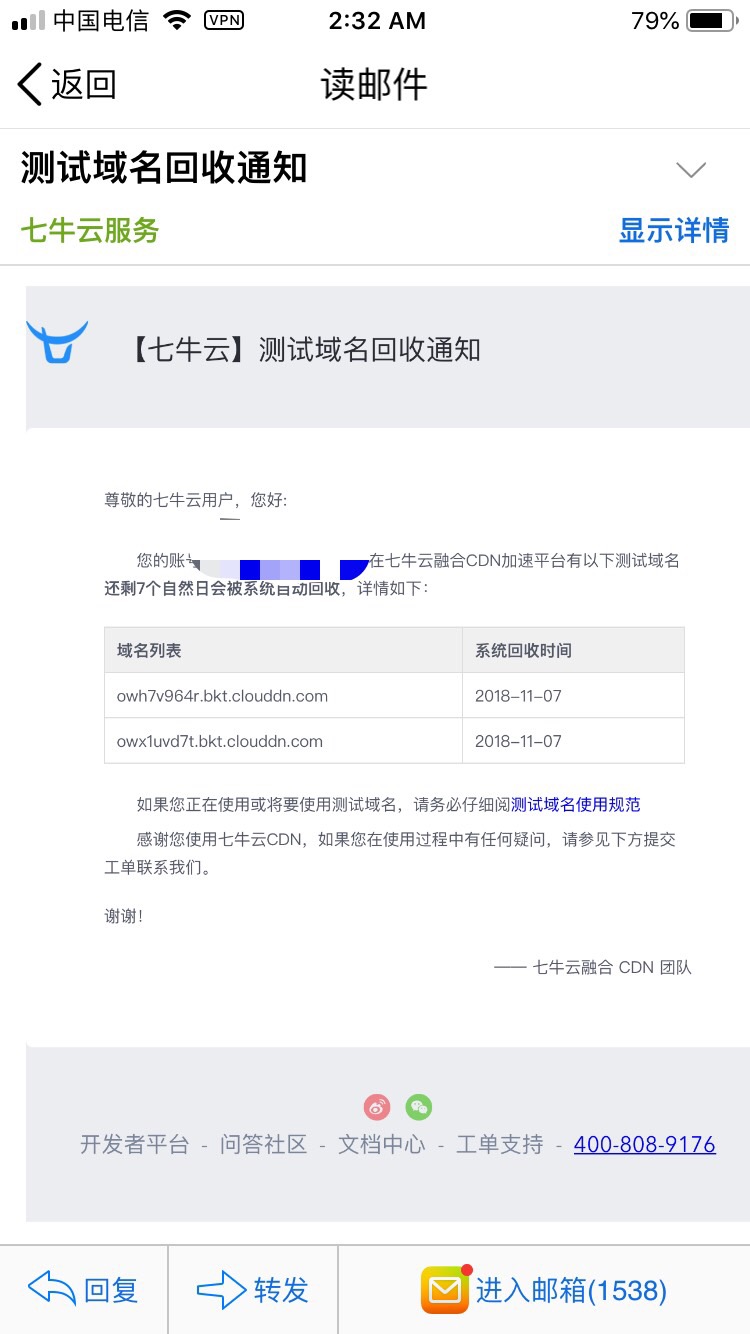
写在前面 前两天收到一份邮件,七牛云 发来的,说是要回收我的测试域名,之前也不知道有测试域名这一说,可能怕有人干坏事吧。总之也就是说,我之前上传在七牛云 上的博客图片可能都要挂掉了。想想自己博客的文章图片都 404 就悲催。
有两个解决方法:
1.在七牛云上提交自己的域名,不过需要备案
对于第一种方式是最简单的,换自己的域名就可以了,但是得备案,最烦就是备案了,一堆恶心的认证操作,而且总感觉背后有人在盯着你 - -
所以果断选择第二种解决方式,使用 Python 把图片爬取下来,转移阵地。
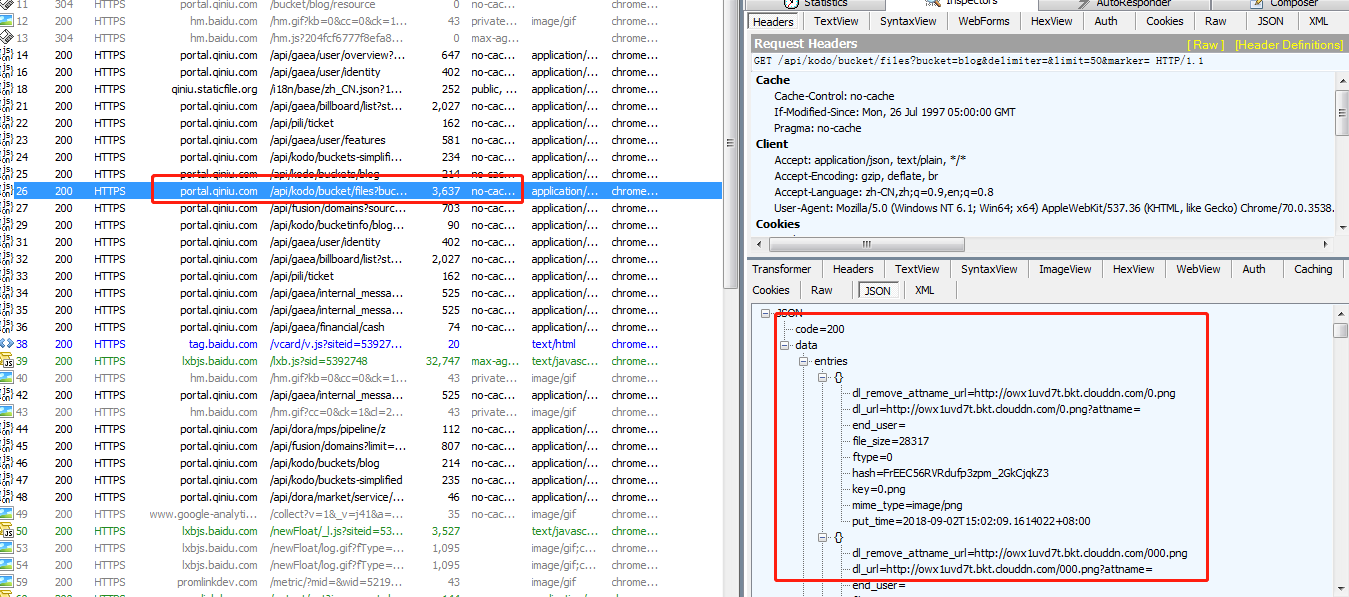
分析七牛云存储空间 通过这个存储的链接中 https://portal.qiniu.com/bucket/blog/resource 抓包可以看到,这个URL https://portal.qiniu.com/api/kodo/bucket/files?bucket=blog&delimiter=&limit=50&marker= 会返回存储数据,也就是图片地址和名称,正是我想爬取的东东。
一次请求可以获取到 50 条数据,那么想要获取全部怎么办呢?
简单分析一下,每次返回的 Json 字段中有 marker=eyJjIjowLCJrIjoiMi5wbmcifQ== ,当点击加载更多的时候,这个marker字段的值会作为下一次请求的 marker 参数值(携带在URL上),直到请求到最后 marker 为 “” ,也就是说当 marker 值为 “” 的时候,就是请求到最后的数据了。没有更多了。
大概了解了之后,就废话不多说了,开抓…
开始抓取七牛云图片 定义属性 header 和 urls,假装自己是浏览器和有cookie信息。
1 2 3 4 5 6 7 8 header = { "User - Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36" , "Accept" : "* / *" , "authority" : "portal.qiniu.com" , "Accept - Encoding" : "gzip, deflate" , "cookie" : "PORTAL_VERSION=v4; _ga=GA1.2.2072818546.1540316980; SSID=VkI4TTMzWE1GUlgzUVRENTZVNTNGQlVQQkVDREZISUpaSDlOWiwxNTQwOTc3OTMzMzk4NDY1MTg3LDViYWVkODRhMWNjZDcyZTJiY2IxMDY2YTlhYWJkOWE2OTliODRkN2EyOGQ2YTUxNWZkYjA5YzZmMTFjZGViMzAyM2JhOGU4NzcyYzU3YTI1ZDIxOWIxMDA4M2UzNGNhNTI3MDhlMmRmOGYxZDdkMDY5YzhkMzU1MzZiM2JlMzUy; PORTAL_UID=1381258456; _gid=GA1.2.1455782183.1540980965; gr_user_id=0dac03ae-d047-4009-8c28-af324447f4b1; qiniu_seo_refer=https://mail.qq.com/; Hm_lvt_204fcf6777f8efa834fe7c45a2336bf1=1540977888,1540980965,1540981082,1540996618; LXB_REFER=mail.qq.com; PORTAL_SESSION=OENCMTBURFVNMjEzV1VaRUdIRk4wTVJFODlMV0QxOEUsMTU0MDk5NjY0NjQwNjIzMzQzMiw5OWFhN2IxNDgwNzhjNDQ5MjRkYTU2ODk1ZDQ4ODQ4ODkxZTQ4Mjgw; _gat=1; __lfcc=1; Hm_lpvt_204fcf6777f8efa834fe7c45a2336bf1=1541004539" } urls = "https://portal.qiniu.com/api/kodo/bucket/files?bucket=blog&delimiter=&limit=50&marker="
因为第一次请求不需要 marker ,所以我们可以给 marker 定义一个默认值,每次请求就更新这个marker,当发现 marker 为空的时候就不再请求了。
请求到的数据只需要图片名称和图片地址就行了,可以用到 json 模块来解析 json 数据,然后将图片下载到blog文件夹:
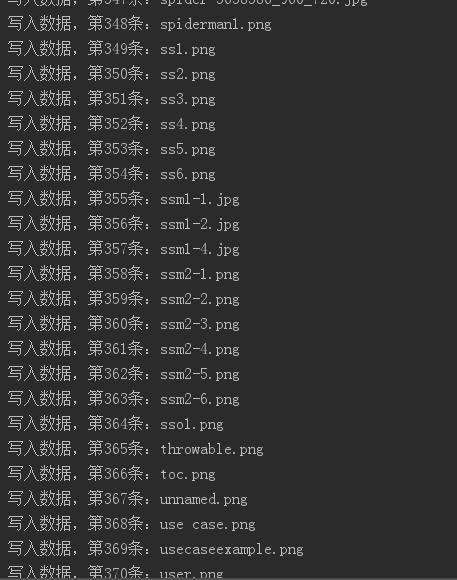
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 marker = "&" os.mkdir("blog" ) os.chdir("blog" ) sum = 0 ; while str(marker).strip()!= '' : url = urls + marker res = request_qiniu(url, header) jsondata = json.loads(res.text) marker = jsondata['data' ]['marker' ] for i in range(0 ,len(jsondata['data' ]['entries' ])): fileurl = jsondata['data' ]['entries' ][i]['dl_remove_attname_url' ] filename = jsondata['data' ]['entries' ][i]['key' ] with open(filename, 'wb' ) as f: img = url_open(fileurl).content f.write(img) sum += 1 print("写入数据,第" +str(sum)+"条:" + filename)
这是请求七牛云数据的方法,用到了 requests 模块:
1 2 3 4 5 6 7 8 def request_qiniu (url,header) : try : response = requests.get(url,headers=header) if response.status_code == 200 : return response return None except RequestException: return None
运行代码开始爬取图片:
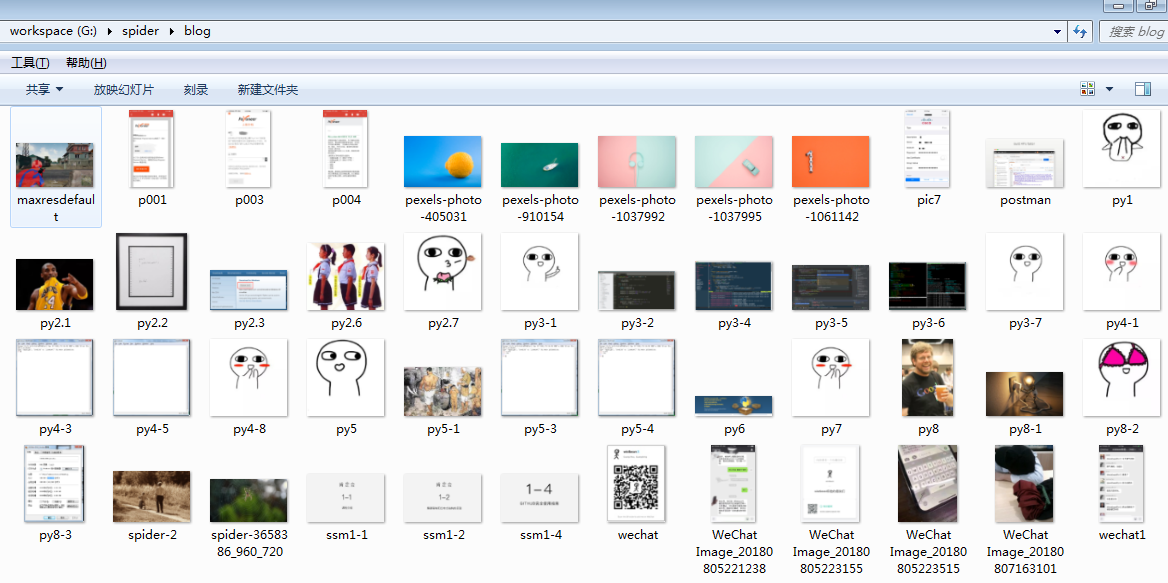
可以看到,创建了文件夹,并且把图片都下载下来了:
ok,搞定!
相关
相关阅读
在公众号「帅彬老仙」发送「帅书」领取我写的技术电子书,转载请注明出处:
wistbean